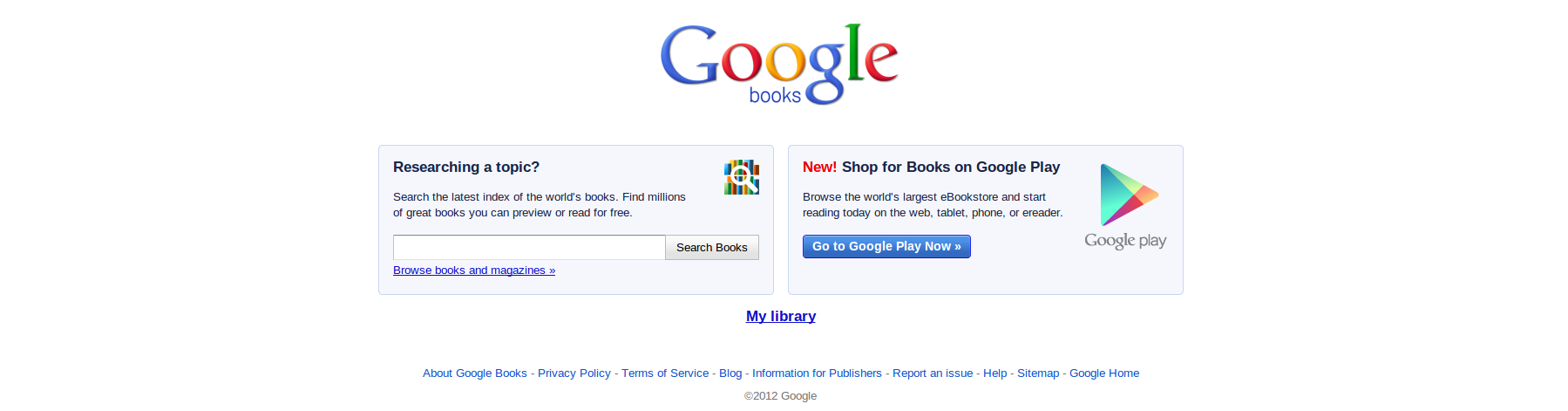
Die Google Books Startseite erlaubt sowohl Google-typisch die freie Suche nach schon bestehenden Werken als auch direkt die Erwerbung neuer eBooks in Google Play:
Google Books
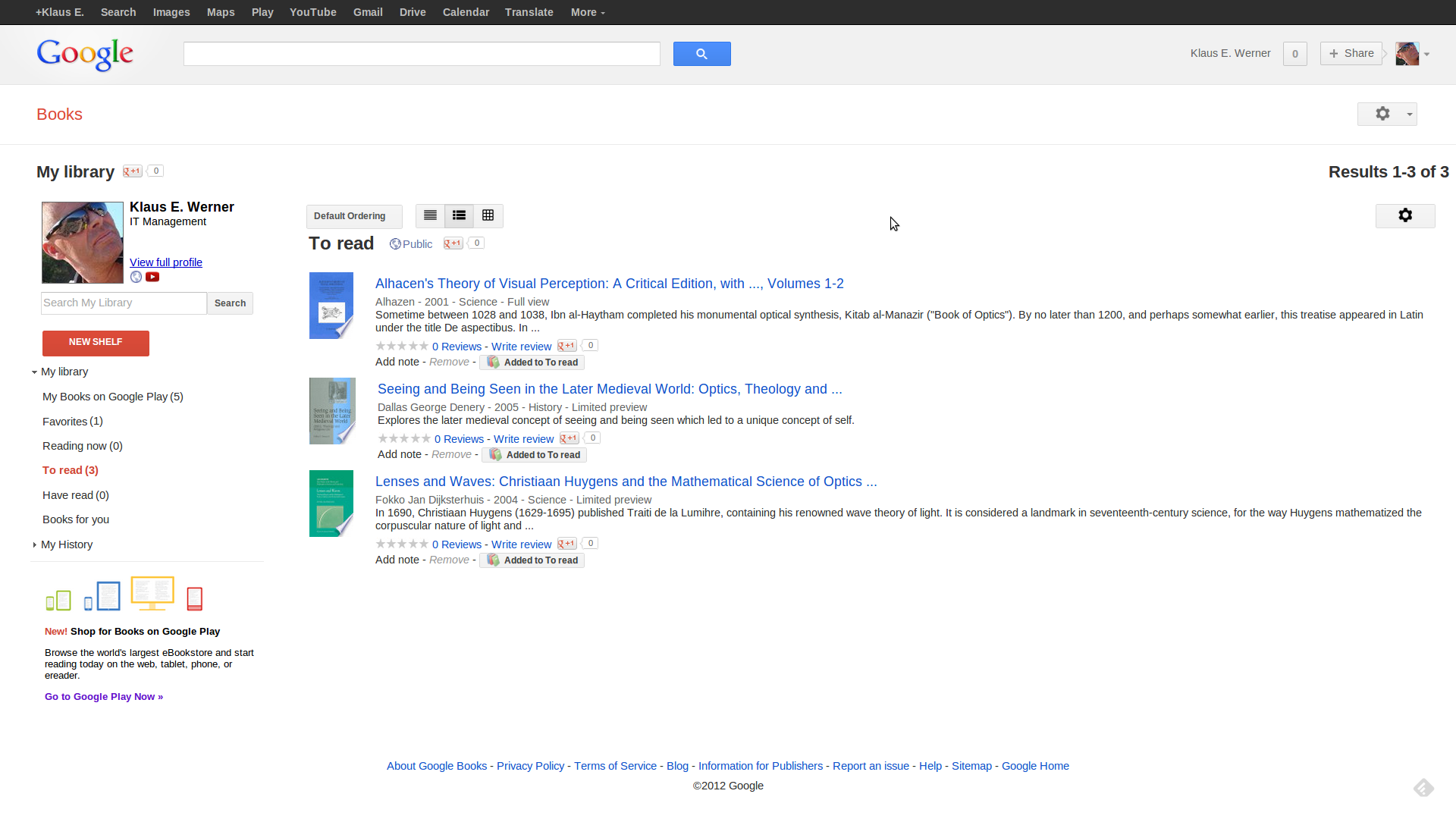
Der häufigste Einsteig wird (zumindest für registrierte Google Nutzer) jedoch über die Google Books Library gehen, eine virtuelle Bibliothek, die sowohl käuflich über Google Play erworbene erworbene als auch freie, in die Bibliothek aufgenommene Werke in mehreren Kategorien auflistet. Dabei können neuerdings auch eigene, bereits existierende eBooks mit einem einfachen Upload integriert werden.
Google Books Library
Die häufigste Suche wird über einen einfachen Suchschlitz im Menü erfolgen, es gibt jedoch auch eine (etwas versteckte) Erweiterte Suche:
Erweiterte Suche
Ist das Gewünschte gefunden, so sind die Möglichkeiten in Google Books zur Anzeige zwar minimalistisch/essentiell, aber in den meisten Fällen de facto ausreichend.
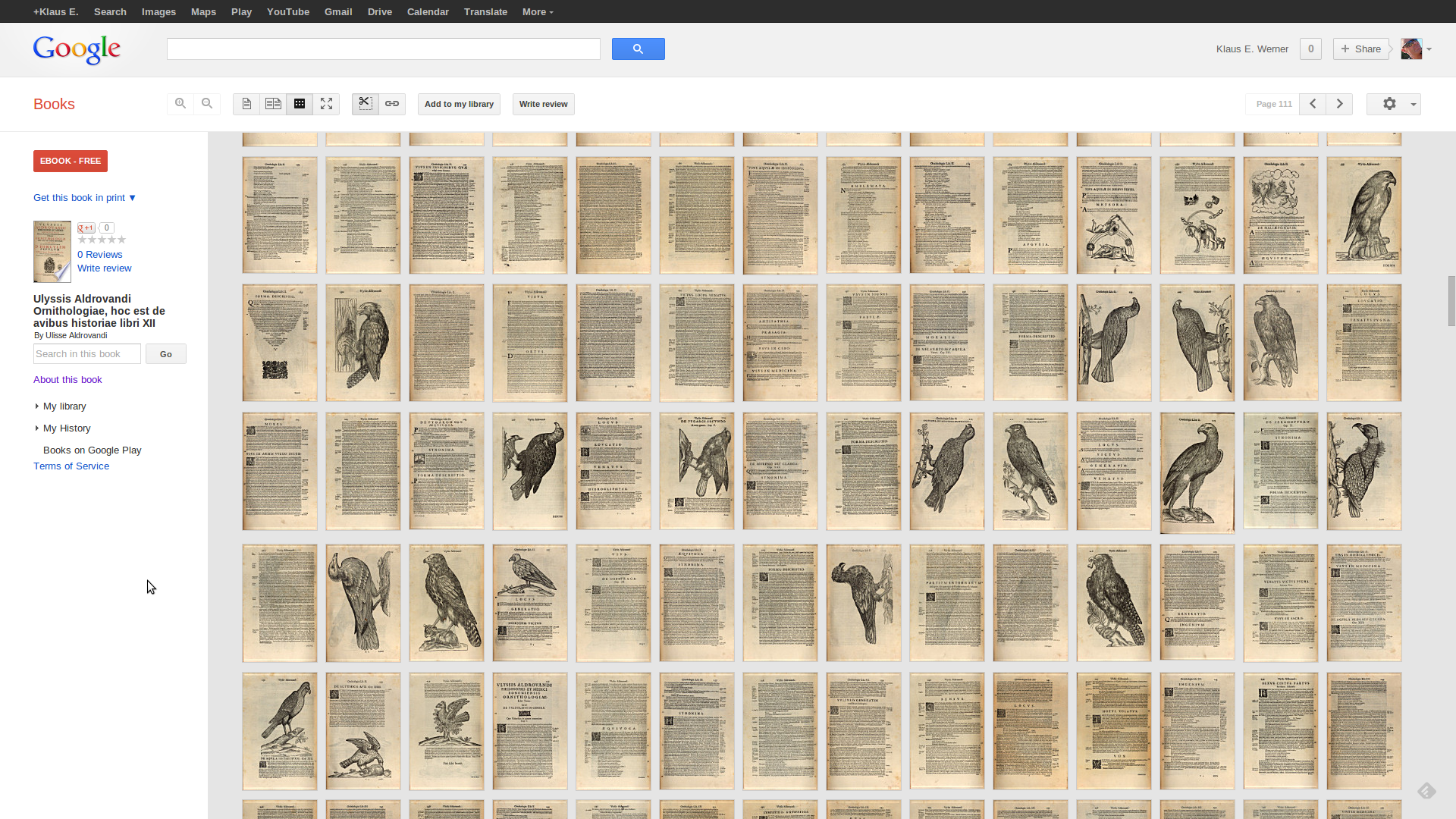
Beispielhaft soll hier die “Ornithologiae, hoc est de avibus historiae” Ulisse Aldrovandis (Bologna 1681), (Google Book) genommen werden.
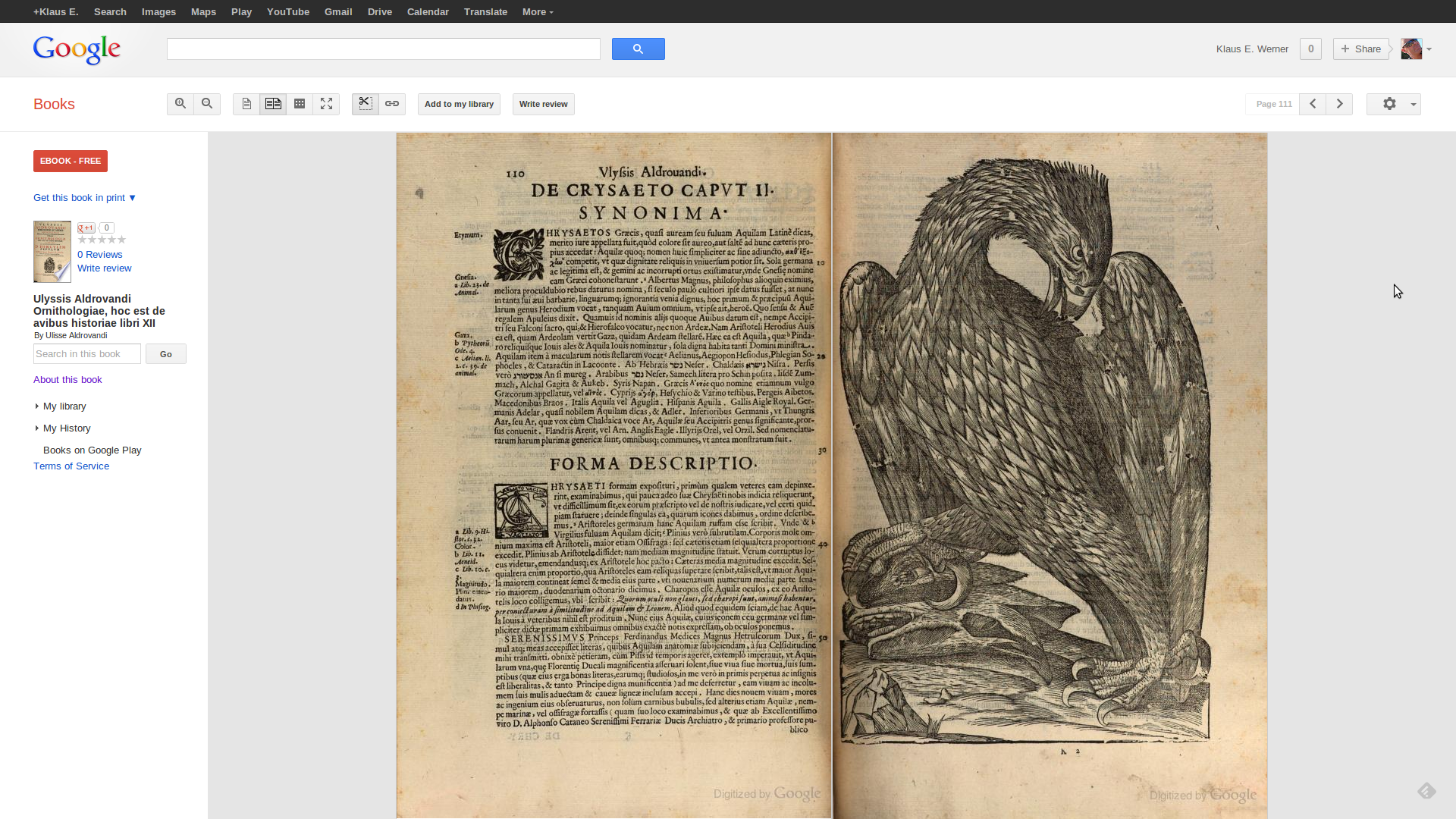
Google Books kann alle in die Google Play Library importierten Werke auch in einem speziellen Web Reader Modus anzeigen, welcher — auf Kosten der sog. sog. navigation bar — erweiterte Navigationsmöglichkeiten innerhalb des Werkes anbietet. Hier eine Ansicht von p.111:
Web Reader
Funktionen
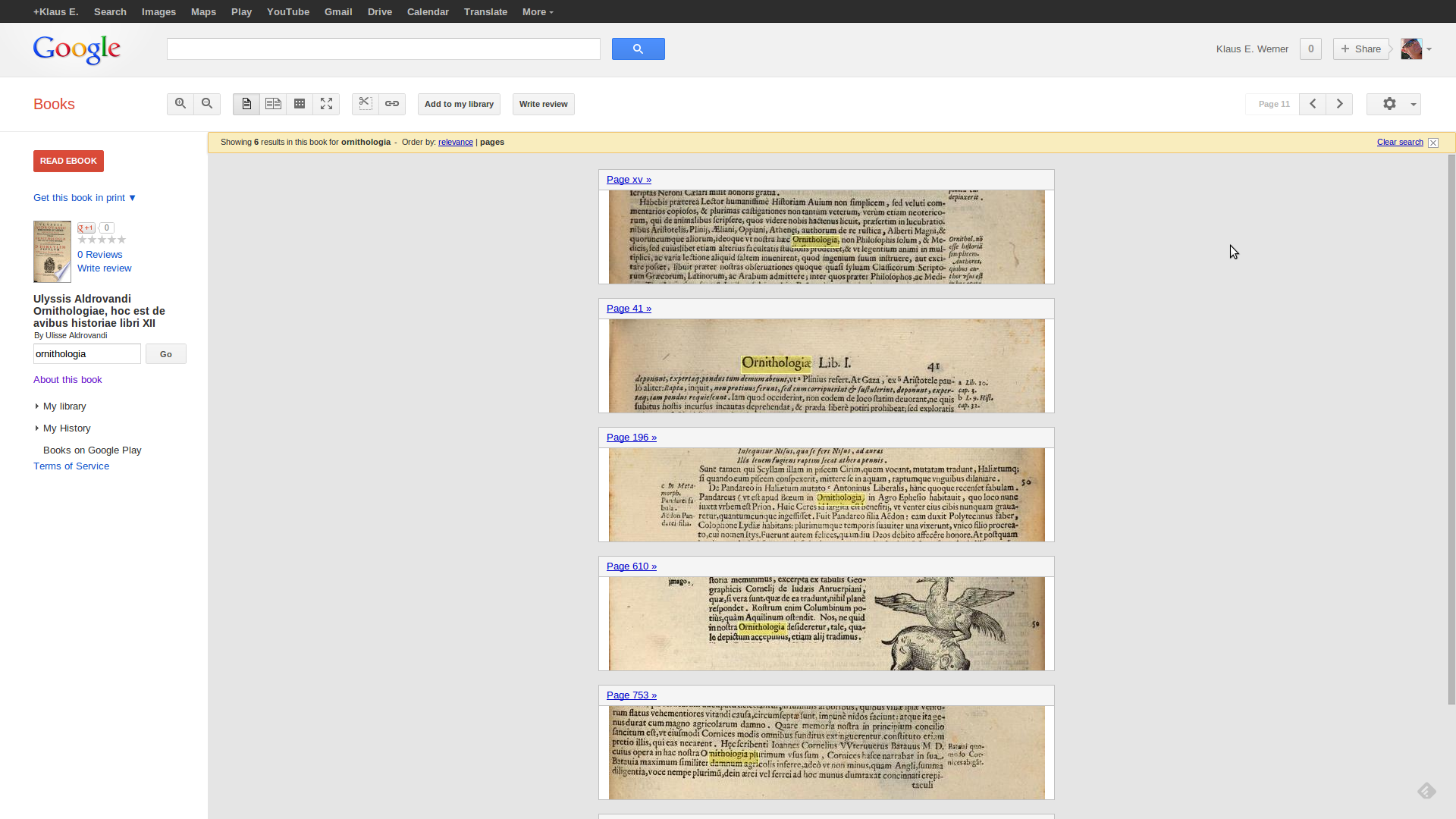
Schon die einfache Buchvorschau ermöglicht ein befriedigendes Navigieren. So kann etwa die Textsuche über alle (sic) Google Books hinweg ausgeführt werden (Suchmaske oben) oder auch nur innerhalb des angezeigten Werkes (Suchmaske links). Als Ergebnis wird eine Auflistung der entsprechend beschnittenen Seiten angezeigt mit der Angabe der Seitenzahl. Die entsprechenden Textstellen werden gelb hinterlegt:
Textsuche in Werk
Gesamtansichten, Einzel- sowie Doppelseiten-Ansichten können seitenweise referenziert werden. Etwa p.111, p.110-111.
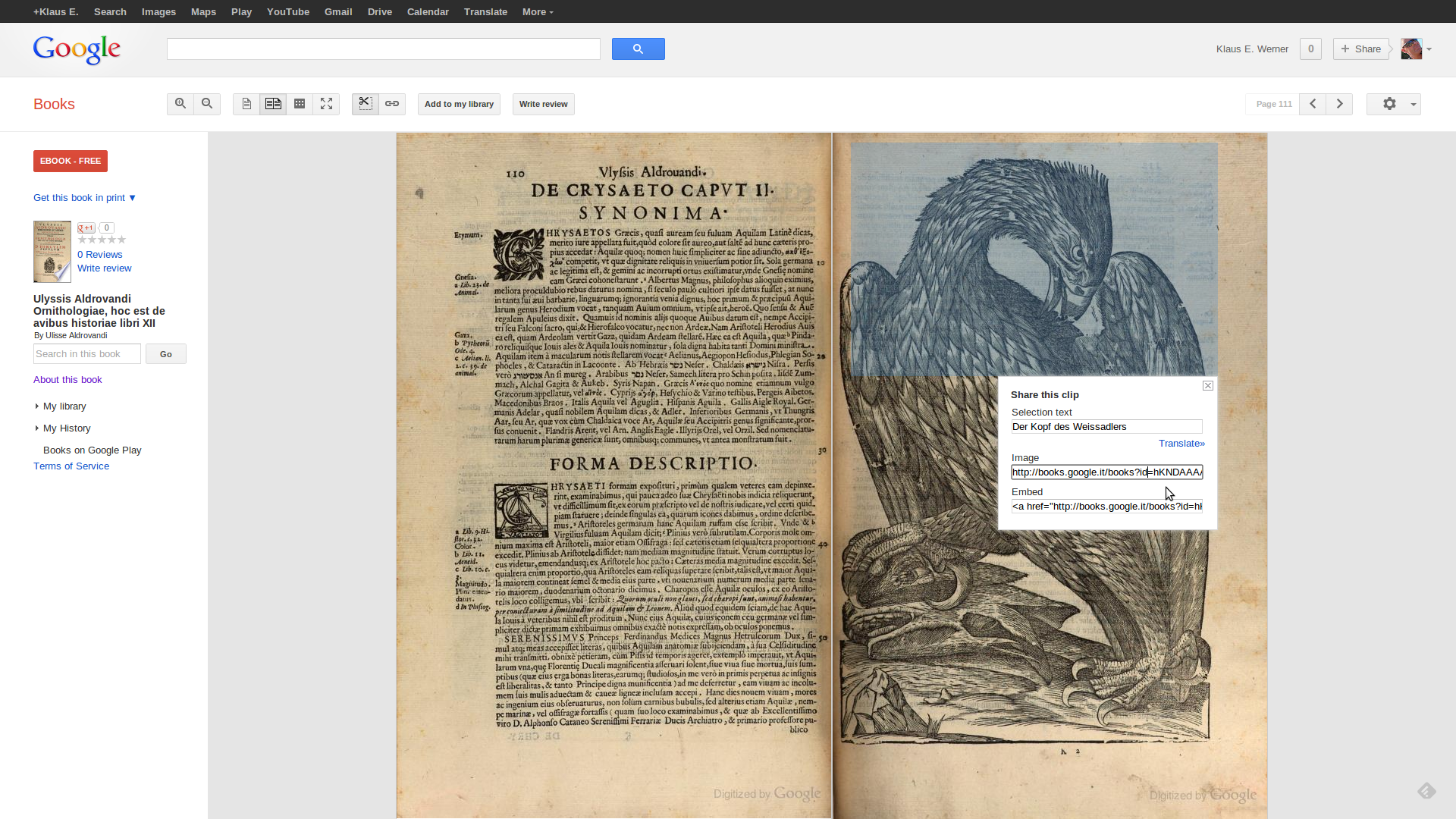
Einzelne Bildelemente können ausgeschnitten und per Email versandt, aber auch in eigene Seiten eingebaut werden, wobei hier ein Link auf die Ursprungsseite verweis. Hier ein Beispiel am Kopf des Weissadlers auf p.111:
Ausschneide- und Referenziermechanismus
Wie erwähnt erlaubt es Google Books, nur die Bilddaten als auch die Bilddaten zusammen einer Referenzierung des Ursprungs zu übernehmen. Hier der resultierende Ausschnitt mit einer Referenzierung auf die Ursprungsseite (beim Klick auf den Link):
Das Gesamtwerk kann – sofern es sich nicht um ein urheberrechtlich geschütztes Werk handelt — zumeist als PDF oder ePub, teils auch als Text heruntergeladen werden, sei es auf die mobile integrierte Plattform (Google Play Library) oder als Datei auf den PC. In diesem Fall – es handelt sich um ein Werk, das sich aufgrund seines Alters nicht als ePub eignet — ist die Arbeit Aldrovandis als DRM-freies PDF erhältlich.
Sollte es sich hingegen um ein Werk handeln, das noch urheberrechtlich geschützt, oder sonstwie noch im Handel erhältlich ist, werden auch entsprechende Händlerlinks angezeigt.
Bei einer Anzeige im Web Reader (also bei in die eigene Google Play Library importierten Werken) sind zusätzliche Funktionen verfügbar: u.a. ein Inhaltsverzeichnis, Einstellungen für die Text- bzw. Scan-Ansicht, eine Such- und Hilfefunktion:
Web Reader mit Index
Zudem können vom Benutzer Bookmarks angefügt und in einer Liste angezeigt werden:
Web Reader mit Liste der Bookmarks
Die vielleicht wichtigste Funktion — die jedoch nur bei neueren eBooks möglich ist, nicht bei gescanntem, retro-digitalsiertem Ausgangsmaterial — betrifft die Möglichkeit, Anmerkungen (“margin notes”) zum Text anzufügen. Hier am Beispiel eines neueren eBooks (Francesco Petrarca, Epistole [2013] ed. U. Dotti):
Web Reader mit Anmerkungen des Benutzers
Das Google’sche Ecosystem ermöglicht es dabei, alle in die Play Books Library importierten Werke auch auf mobile Android Geräten lesen und bearbeiten zu können. Hier die Ansicht der Library auf einem Smartphone:
Mobiler Viewer: Library
Und hier die Leseansicht desselben Werkes (Petrarca) wie im Web Reader:
Mobiler Viewer: Petrarca
Auch werden aktuelle Lesepositionen, Inhaltsverzeichnis, Anmerkungen und Bookmarks automatisch übernommen:
Mobiler Viewer: IndexMobiler Viewer: Liste der AnmerkungenMobiler Viewer: Anmerkungen
Als Einführung sei auf den Aufsatz „Schlagwort UND Klassifikation“ hingewiesen. Die Überarbeitung der Klassifizierung ist hier dokumentiert (Link, Screenshot, PDF). Hier ein Blick auf die alte Systematik:
Aa LEXIKA
Ab BIBLIOGRAPHIEN
B SCHRIFTLICHE ÜBERLIEFERUNG – ARCHIVALIEN
C KUNSTSAMMELN – KUNSTVERWALTUNG
D KUNST & ANDERE GEBIETE
E ÄSTHETIK – KUNSTTHEORIE – KUNSTWISSENSCHAFT
F SOZIOLOGIE DER KUNST
G MATERIAL & TECHNIK
H MORPHOLOGIE
Ik IKONOGRAPHIE
Ka KUNST ALLGEMEIN
Kb ARCHITEKTUR
Kc ARCHIT.-PLASTISCHE ANLAGEN
Kd PLASTIK
Ke MALEREI
Kf GRAPHIK – BUCHWESEN
Kg ANGEWANDTE KUNST
Kh PHOTOGRAPHIE & FILM
Ki THEATER
Kk NEW MEDIA
Bei der Erstellung der Neuen Systematik waren drei Fälle zu beobachten:
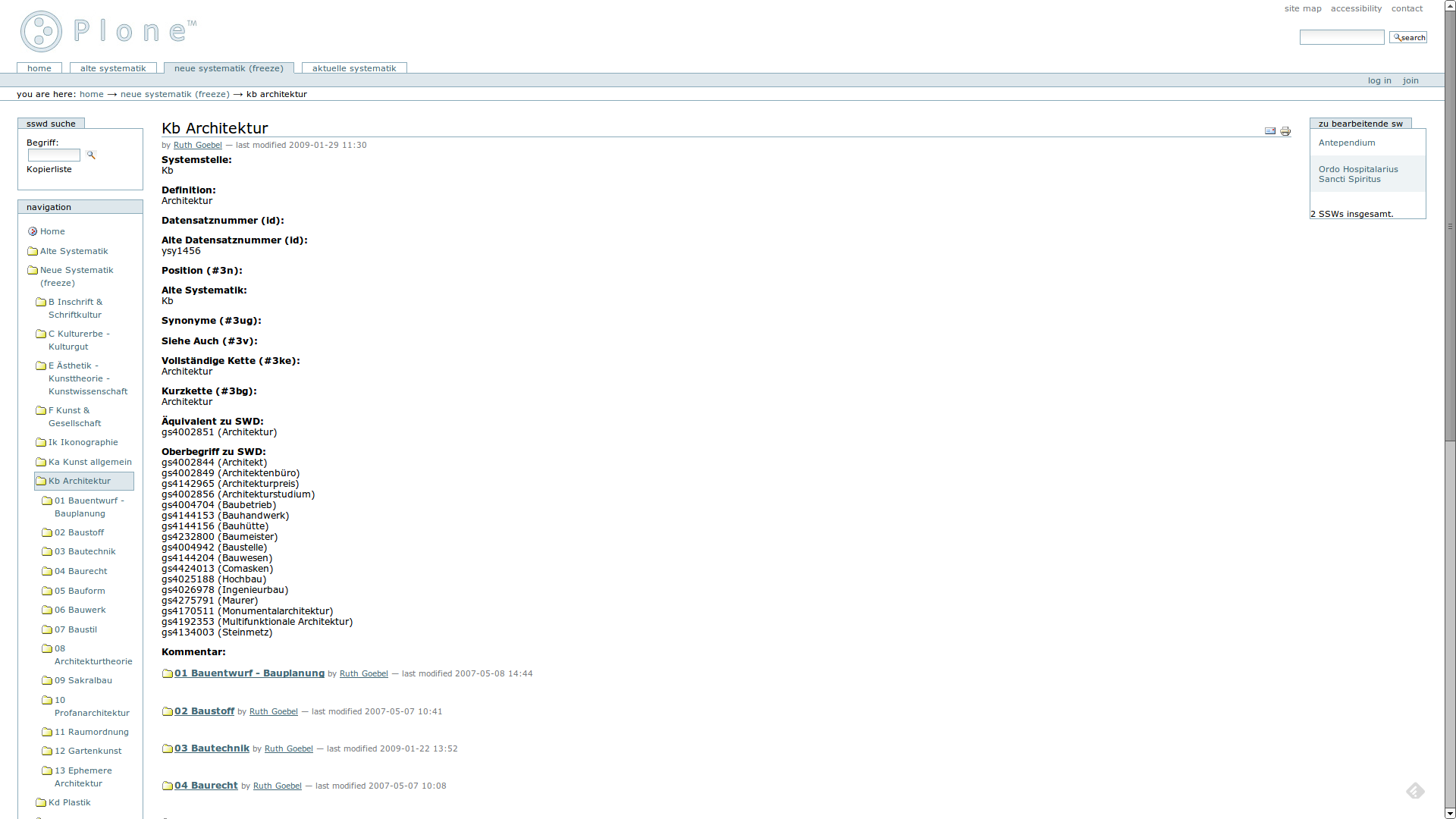
Eine 1:1 Übereinstimmung einer Klasse der Neuen Systematik mit einem Schlagwort der SWD.
Hierzu gehört etwa die Klasse Kb Architektur (Plon, Screenshot) mit dem äquivalenten SWD Schlagwort Architektur.
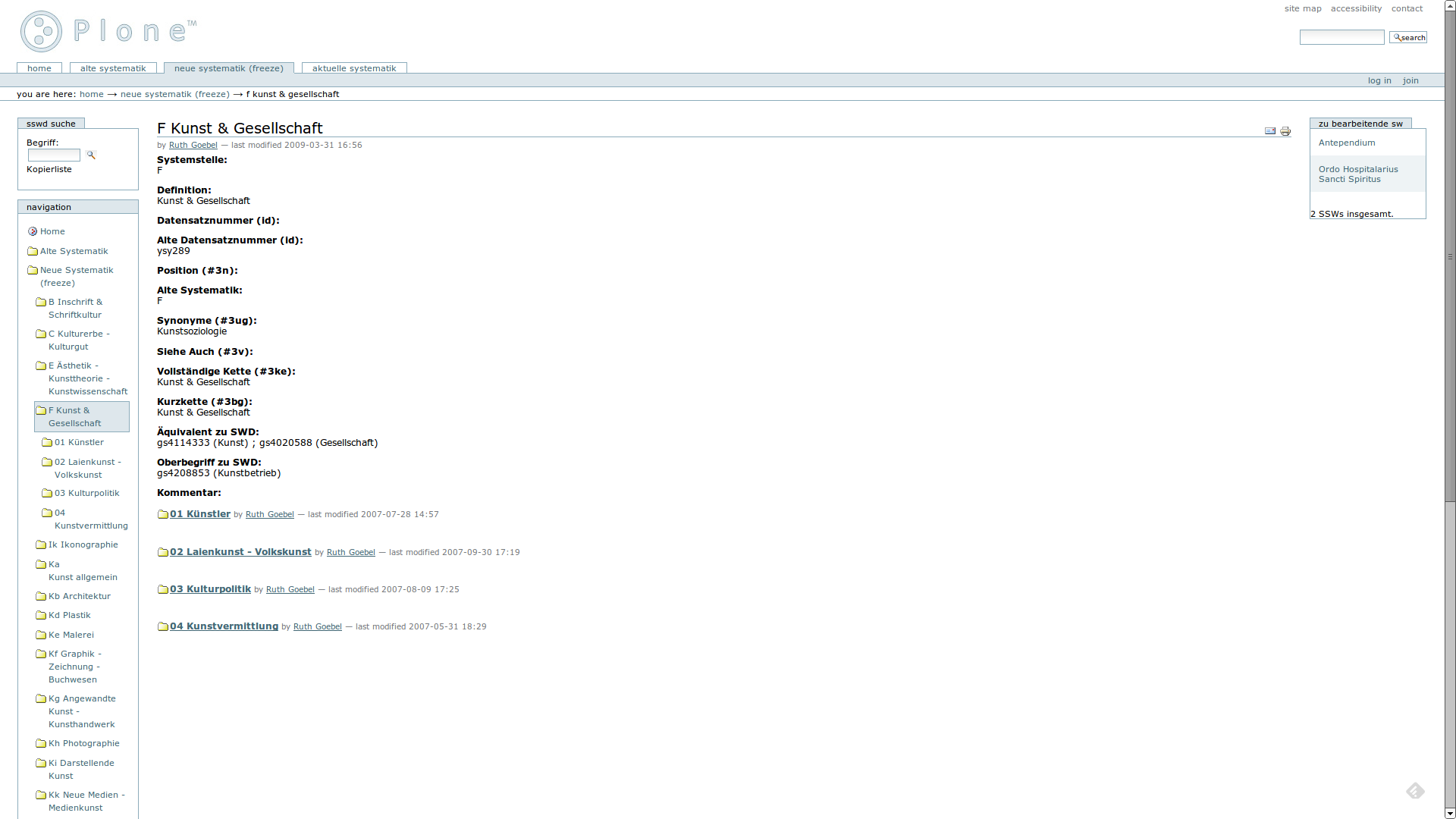
Eine Übereinstimmung einer Klasse der Neuen Systematik mit einer Kombination aus mehreren SWD Schlagworten.
Hierzu gehört etwa die Klasse F Kunst & Gesellschaft mit der äquivalenten Kombination aus den beiden SWD Schlagworten Kunst und Gesellschaft (Plon, Screenshot).
Der eher seltene Fall, daß sich keine äquivalentes Schlagwort finden liess: in diesem Fall wurde die Klasse dennoch verwendet und versucht, zumindest die jeweiligen Unterklassen mit der SWD zu verbinden.
Hierzu gehört etwa die Klasse E Ästhetik – Kunsttheorie – Kunstwissenschaft (Plon, Screenshot), zu der äquivalente SWD Schlagworte fehlen. Zu den Unterklassen im Systematikbaum — 01 Kunstphilosophie, Ästhetik & Kunstanschauung, 02 Kunsttheorie & Kunstliteratur, 03 Kunstwissenschaft, 04 Künste & Kunstgattungen, 05 Künstler & Kunstwerk, 06 Kunst & Wissenschaft — gibt es jedoch teilweise wieder SWD Äquivalente.
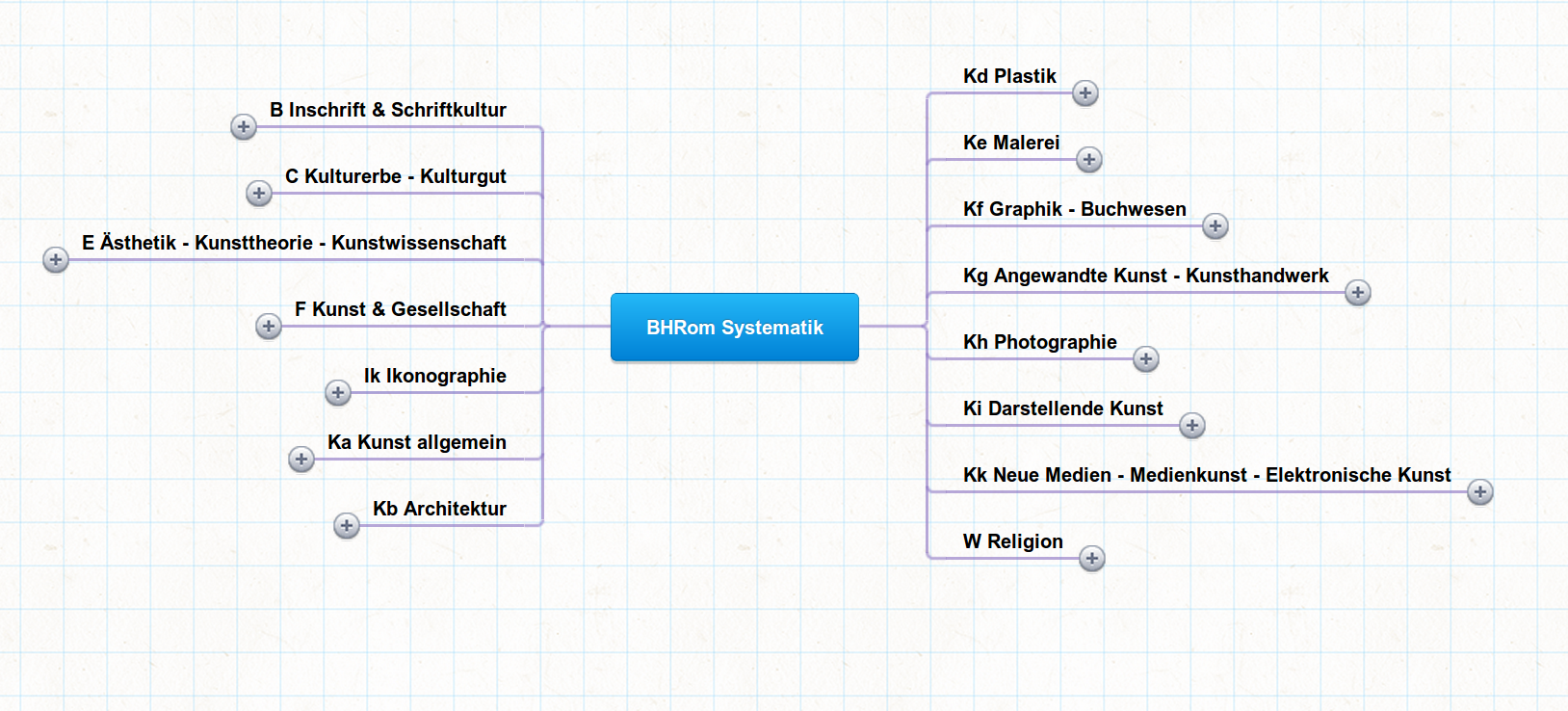
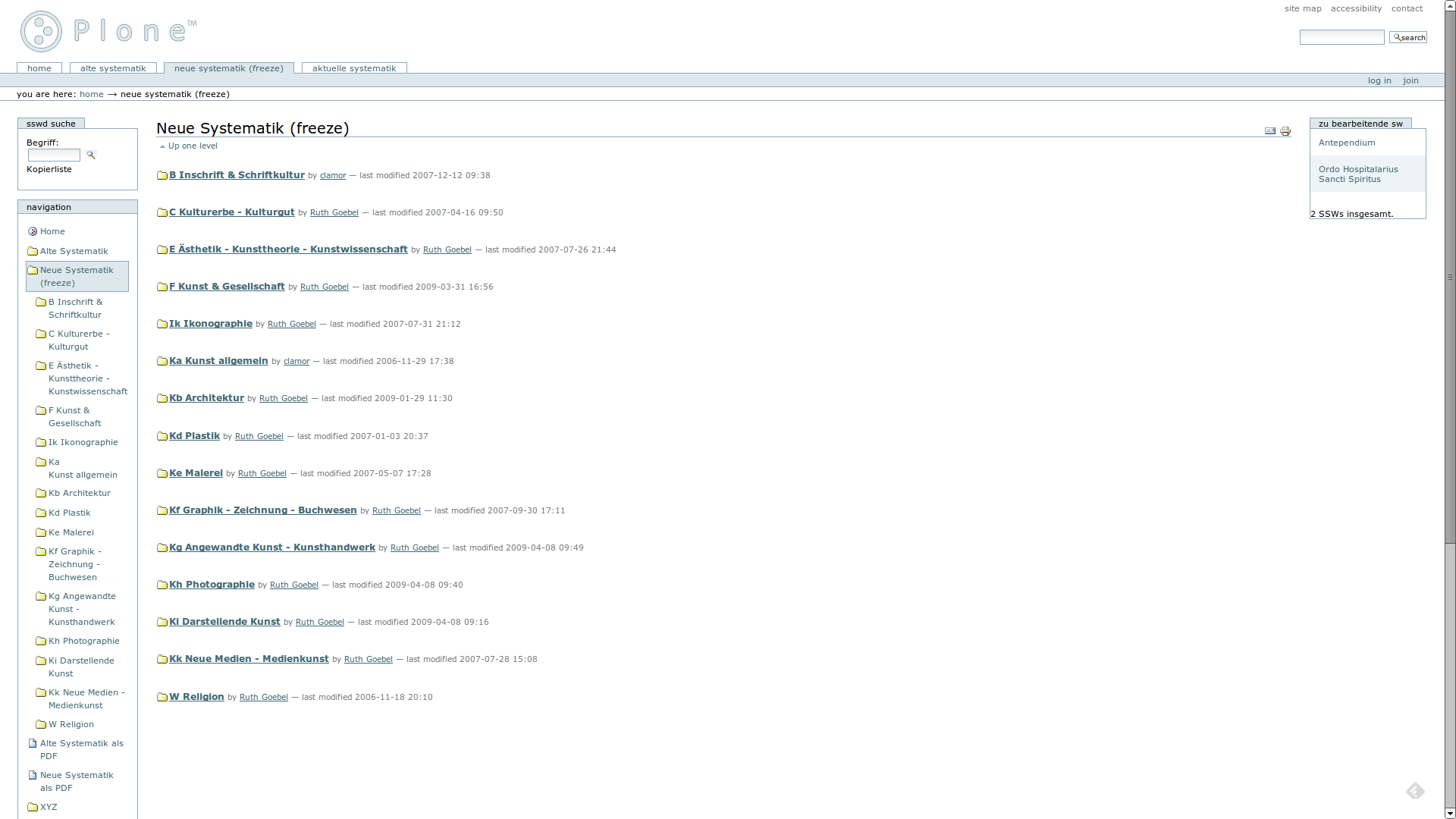
Die finalisierte Systematik ist hier (Screenshot) abgelegt. Dazu gibt es eine komprimierte Auflistung der verwendeten Begriffe als PDF (Konvertierung in HTML). Hier als Überblick die Oberklassen:
B Inschrift & Schriftkultur
C Kulturerbe – Kulturgut
E Ästhetik – Kunsttheorie – Kunstwissenschaft
F Kunst & Gesellschaft
Ik Ikonographie
Ka Kunst allgemein
Kb Architektur
Kd Plastik
Ke Malerei
Kf Graphik – Zeichnung – Buchwesen
Kg Angewandte Kunst – Kunsthandwerk
Kh Photographie
Ki Darstellende Kunst
Kk Neue Medien – Medienkunst
W Religion
Graphische Visualisierung als MindMap
Die hierarchische Struktur der Neuen Systematik eignet sich vorzüglich für eine Anzeige als Mindmap. Verschiedene Ansätze wurden dazu geprüft:
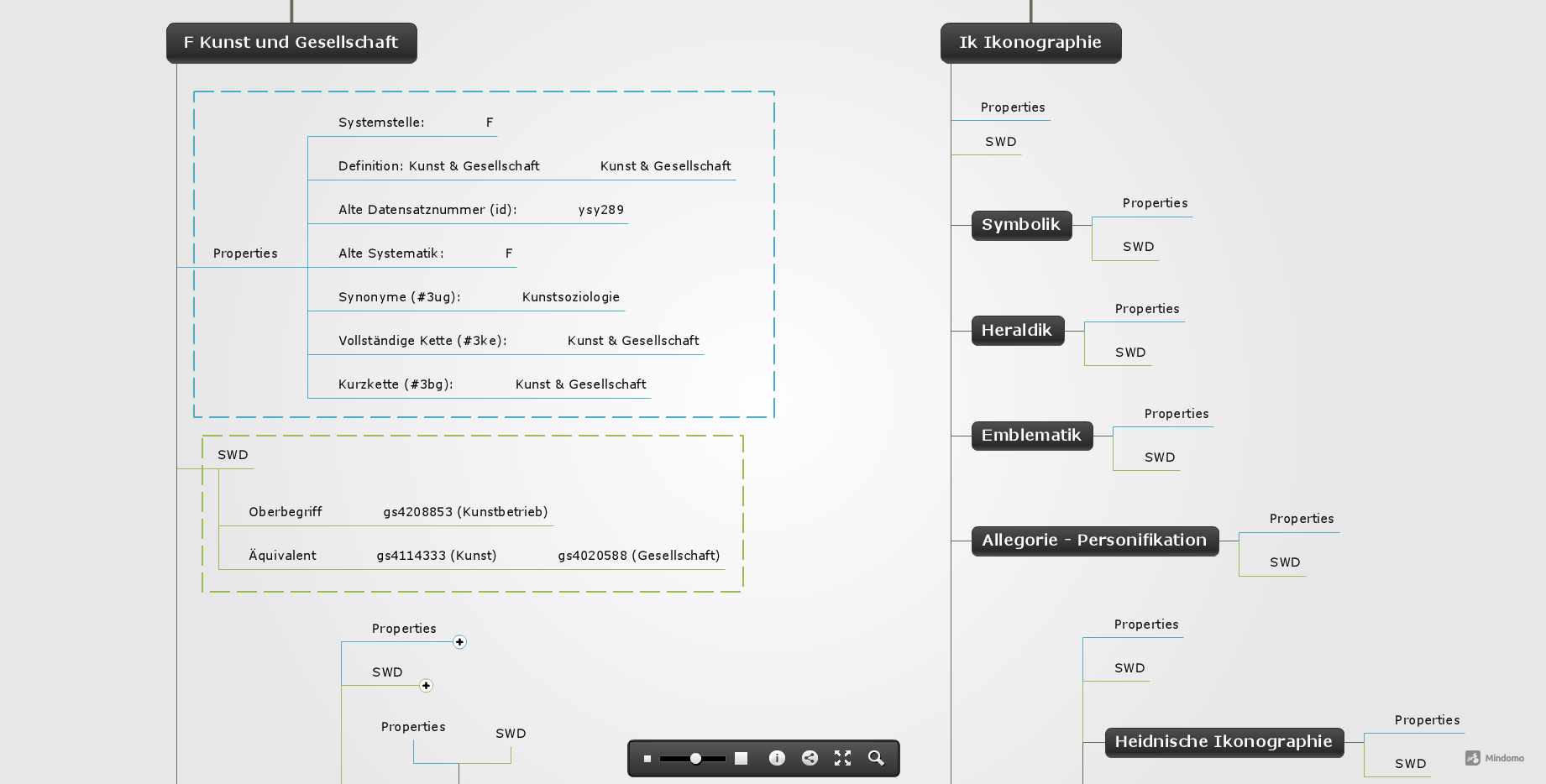
die Klasssen und jeweils daran angebunden alle ihre Eigenschaften einschliesslich der SWD Schlagworte (Mindomo, Screenshot, Ausschnitt);
die Klassen simplifiziert mit SWD Schlagworten (violett) als eigene Knoten (Mindomo, Screenshot);
eine Ansicht mit Referenzierungen auf eine separate SWD Schlagwortliste (rechts, violett) (Mindomo, Screenshot, Ausschnitt).
Gut erkennbar wird hierbei die grundsätzliche diverse Struktur der beiden Systeme, die nur verknüpft (referenziert), aber nicht deckungsgleich übereinandergelegt werden können.
Benutzfreundlicher ist jedoch eine übersichtliche Anzeige des gesamten Baumes unter Verzicht auf die übermäßig komplexe Darstellung der jeweiligen SWD Abhängigkeiten. Dies ermöglicht es, die komplette Struktur der Neuen Systematik in einer einzigen Mindmap zu generieren. Hier ein Screenshot mit den Zweigen noch eingeklappt:
Mind42 Mindmap (kompletter Datensatz)
Hier ein Ausschnitt. Und hier ein Link auf die gesamte Mindmap auf Mind42.
Listenansicht
Ein ganz anderer Weg ist die Erstellung einer aufklappbaren Listenansicht — wie etwa hier in einer frühen Version (Screenshot). Eine solche Listenansicht kann bei Bedarf (mouse over) auch die SWD Informationen einblenden sowie Links auf Kubikat aufrufen. Hier unten ein Screenshot (Life-Version):
Liste mit Link auf Kubikat und zusätzlicher Angabe der SWD Schlagworte
Verwendung zur parataktischen Konsultation anderer Systeme
Die Möglichkeit, die selbst entwickelte, proprietäre Systematik über die SWD Schlagworte mit regulären OPACs zu verbinden, macht das System zur Verwendung in verschiedenen Szenarien interessant. So kann die proprietäre Systematik etwa …
mehrsprachig sein;
auf spezielle Bedürfnisse zugeschnitten sein;
verschiedene (auch fremde oder anderssprachige) OPACs über die SWD abfragen;
modifiziert werden ohne die zugrundeliegende Datenbasis anzufassen.
Bei den meisten Systemen kann ein Link auf einen bestimmten OPAC Eintrag (semi-)automatisch gebildet werden.
Für die Anwendung des hier vorgeschlagenen Systems ist es demnach lediglich nötig, die spezifische Struktur der URL zu wissen, also etwa:
Bei nicht deutschsprachigen OPACs muss das Schlagwort natürlich übersetzt werden. Wenn die Suche nach Kulturpolitik auf die Ressourcen der Getty Research Library übertragen werden soll, muss nach “cultural policy” gesucht werden (n.b. die Anführungszeichen sind hier nötig!):
Wie schon ein kurzer Test zeigt, fallen die Ergebnisse positiv aus: die Klassen (bzw. umgesetzt dann Schlagworte) Künstler, Kunstvermittlung und Kulturpolitik geben wie zu erwarten sehr nutzbare Ergebnisse; Kunst und Gesellschaft ebenfalls, da hier die Kombination Kunst & Gesellschaft ausgewertet wird; zu Laienkunst – Volkskunst hingegen gibt es keine Äquivalenzen in der SWD und auch keine deutschsprachigen Resultate.
Export/Austauschformate
Als Austauschformat eignet sich bislang das Freemind Format am besten, da es XML basiert und gut dokumentiert ist (Demo, FreeMind User Guide by Shailaja Kumar). Zudem ist hier ein hervorragender Desktop Editor vorhanden (Freemind), der auch in eine Vielzahl von Formaten exportiert:
Editieren mit Freemind
Das Freemind-Format ermöglicht es, sowohl die hierarchische Struktur der Systematik als auch, bei Bedarf, die äquivalenten SWD Schlagworte abzubilden. Im untenstehenden Beispiel sind die Font-Anweisungen zum besseren Verständnis grau ausgeblendet.
Alternativ sind natürlich auch Mind42, Mindmeister etc. benutzbar, die jedoch proprietäre (und teils auch binäre) Formate benutzen, dafür jedoch direkt im Browser ausgeführt werden können.
Eine Weiterentwicklung dieses Formates, ev. auch mit Schema-Anbindung, sowie die Bereitstellung von XSL-T Transformationen ist angedacht. Eventuell wäre auch eine kleine Web-Plattform zum Austausch verschiedener solcher Systematiken von Nutzen, bei dem sich Bibliotheken schnell eine für sie optimale Systematik runterladen bzw. zusammenstellen könnten.
Download
Zur Zeit stellen wir die ff. Datenformate zum Download bereit:
Als reine Endprodukte zur raschen Konsultation, aber nicht zur Weiterverarbeitung, sind auch Text-, Grafik- und Bildformate geeignet. Hier einige Textformate zum Download:
The following is an efficient way to prepare scanned book or manuscript pages for use in digitization projects. In fact, it’s kind of a shortcut to have a fast workflow which nonetheless allows for visual control of quality issues.
RAW Input
The input files should always – repeat: always – be RAW files, at least if the digitizations are done by commercial cameras using CMOS sensors. In case of dedicated scanners TIFFs will be the only available output.
In either case, aim for the best available gamut setting (like AdobeRGB color space) and a fitting file format, like 12bit or 14bit for NEFs and CR2s – or whatever your RAW formats are – and 16bit for TIFFs generated from scanners. In case of the latter, LZW compression does wonders without inflicting losses.
A conversion into the DNG format is not useful and in fact to be avoided because it does not preserve the original output stream from the camera sensor or the scanner but instead only its conversion and interpretation. Different DNGs generated from the same RAW file – say: in 2008, in 2012 and 2014 – are in fact different.
Preserving Recto/Verso
Front and back sides of scanned pages should be saved in separate directories, aptly named recto and verso. Some operations like renaming and cropping will be much faster this way.
Your folder will thus have the following structure:
root
└signature
└recto
└verso
Obviously, this is not necessary if you always scan both pages of a book in a single operation.
Image Operations
For the following operations I will be using Aftershot Pro, originally developed by Bibble but now (unfortunately) in Corel’s hands. FLOSS software like Darktable is obviously preferrable and I might change my workflow accordingly.
We don’t need no separate import operation, as Aftershot allows direct access to the recto and verso folders. This comes handy and is – at least in our case, where keywords and metadata are not much important – much better than, say, Lightroom’s or Capture One’s behaviour.
Right now, I apply the following operations. Some of these are important only if your are using camera devices like the »Wolfenbütteler Buchspiegel« which use a mirror. Here is a link to the relevant Aftershot Presets files stored in .AfterShotPro/Presets/.
Mirroring
Recto
Verso
White Balance
EV & Perfectly Clear
Wavelet Sharpen
Copyright Information
Fortunately, the possibilities of a RAW developing engine like Aftershot allows for intensive fine tuning and instant control.
Cropping
Nearly always there will be the need to crop the images because they do not show the 2:3 ratio of FF cameras. Aftershot allows to do this once, copy the crop settings and and to apply them to the rest of the images.
Renaming Files
As the files are for now in sequential order only and both recto and verso need to be brought together, we will have to rename them.
Here is the schema used in Aftershot: [opath-2]-[3rseq]-[opath-1]
Export
Exporting the files is only for specified workflows, e.g. the generation of PDF’s via convert -compress jpeg -quality 75 -limit memory 22000 *.jpg [filename].pdf. These PDFs may be enhanced with indices as described here.
Please note that exports are not in any way suitable to serve as archival formats: only the RAW files (maybe accompanied by the XMP sidecar files generated by Aftershot) represent the original captured data.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Screenshot]](http://files.kewerner.name/systematik/Screenshot26.png){kind=link}
![[Screenshot]](http://files.kewerner.name/systematik/Screenshot27.png){kind=link}
![[Screenshot]](http://files.kewerner.name/systematik/Screenshot28.png){kind=link}
![[Screenshot Detail]](http://files.kewerner.name/systematik/Screenshot29.png){kind=link}
![[Screenshot]](http://files.kewerner.name/systematik/Screenshot30.png){kind=link}
{kind=link}
![[Screenshot]](http://files.kewerner.name/systematik/Screenshot31.png){kind=link}
{kind=link}
{kind=link}
{kind=link}